
Pandas Alternatives : Modin
Pandas library has became the “one must installed” library for data manipulation in python and is widely used by data scientist and analyst. Pandas provide an easier way to do preprocessing and analysis on our data. However, there are times when the dataset is too large and Pandas may run into memory errors. The primary reason for the slowdown is pandas can’t run the program parallelly, and it only uses one CPU core for running the program. We have to shift to distributed computing platforms like Spark for working on large data.
Modin is an open source library developed by UC Berkeley’s RISELab to speed up the computation by distributive computing. Modin uses Ray/Dask libraries in backend to parallelize the code and also we don’t need any distributive computing knowledge to use Modin. Modin Dataframe has a similar API to Pandas. So all we are to do is to continue using Pandas API as was before. Modin provides the speedup of upto 4x on 4 core laptop. Modin can be used for dataset size ranging from 1MB to 1TB.
By simply replacing the import statement, Modin offers users effortless speed and scale for their pandas workflows:

To learn more about the speedups you could get with Modin and try out some examples on your own, check out our 10-minute quickstart guide to try out some examples on your own!
Installation
Modin can be installed with pip on Linux, Windows and MacOS:
pip install modin[all]
Pandas API Coverage
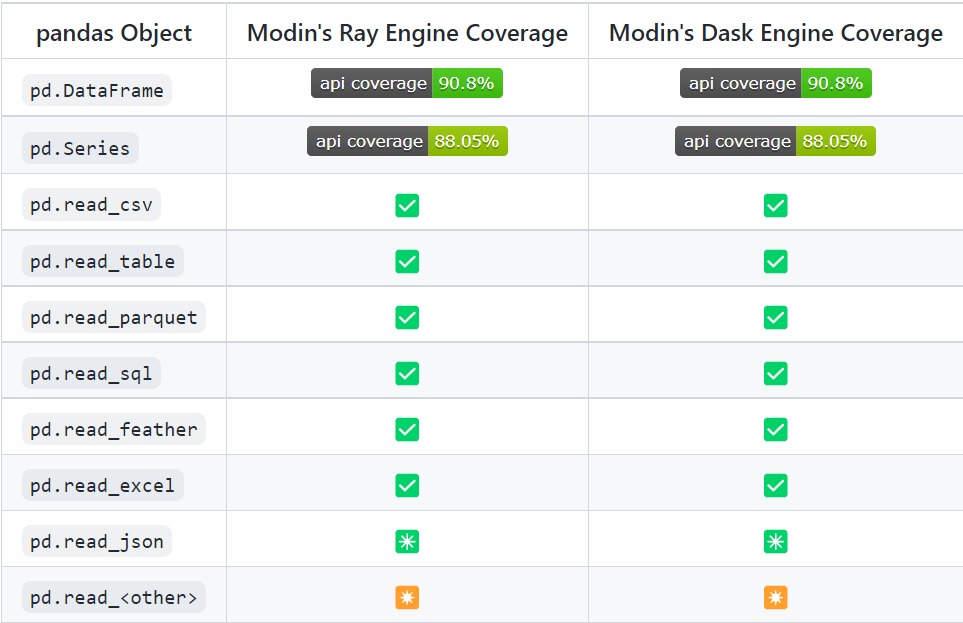
For the functions that are not implemented in Modin, they automatically default to pandas. So for the functions that are not implemented in pandas and for user-defined functions(apply functions in pandas), Modin will convert the Modin DataFrame to Pandas DataFrame and then apply those functions. There will be some performance penalty for converting to Pandas Dataframe.
Faster pandas, even on your laptop
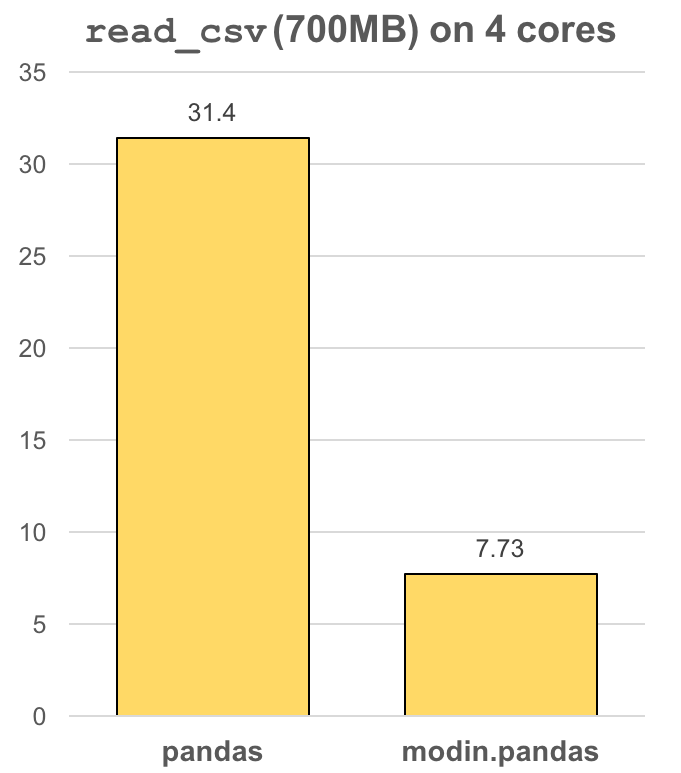
The modin.pandas DataFrame is an extremely light-weight parallel DataFrame. Modin transparently distributes the data and computation so that you can continue using the same pandas API while working with more data faster. Because it is so light-weight, Modin provides speed-ups of up to 4x on a laptop with 4 physical cores.
In pandas, you are only able to use one core at a time when you are doing computation of any kind. With Modin, you are able to use all of the CPU cores on your machine. Even with a traditionally synchronous task like read_csv, we see large speedups by efficiently distributing the work across your entire machine.
import modin.pandas as pd
df = pd.read_csv("my_dataset.csv")
Modin can handle the datasets that pandas can’t often data scientists have to switch between different tools for operating on datasets of different sizes. Processing large dataframes with pandas is slow, and pandas does not support working with dataframes that are too large to fit into the available memory. As a result, pandas workflows that work well for prototyping on a few MBs of data do not scale to tens or hundreds of GBs (depending on the size of your machine). Modin supports operating on data that does not fit in memory, so that you can comfortably work with hundreds of GBs without worrying about substantial slowdown or memory errors. With cluster and out of core support, Modin is a DataFrame library with both great single-node performance and high scalability in a cluster.

Leave a comment