
K Means
Clustering is a technique widely used to find groups of observations (clusters) that share similar characteristics. This process is not driven by a specific purpose, which means you don’t have to specifically tell your algorithm how to group those observations since it does it on its own. The result is that observations or data points in the same group are more similar between them than other observations in another group. The goal is to obtain data points in the same group as similar as possible, and data points in different groups as dissimilar as possible.
Clustering is an unsupervised learning technique used for data classification. Unsupervised learning means there is no output variable to guide the learning process (no this or that, no right or wrong) and data is explored by algorithms to find patterns. We only observe the features but have no established measurements of the outcomes since we want to find them out.
K Means
K-means clustering is one of the simplest and popular unsupervised machine learning algorithms. K-means looks for a fixed number $k$ of clusters in a dataset. A cluster refers to a collection of data points aggregated together because of certain similarities. You will define a target number $k$, which refers to the number of centroids you need in the dataset. A centroid is the imaginary or real location representing the center of the cluster.
Every data point is allocated to each of the clusters through reducing the in-cluster sum of squares. In other words, the K-means algorithm identifies $k$ number of centroids, and then allocates every data point to the nearest cluster, while keeping the centroids as small as possible. The ‘means’ in the K-means refers to averaging of the data which is to find the centroid.
How K-Means Works
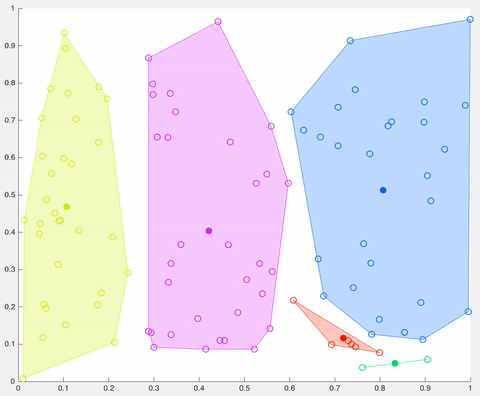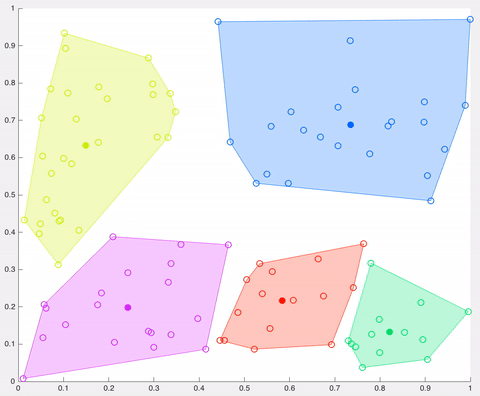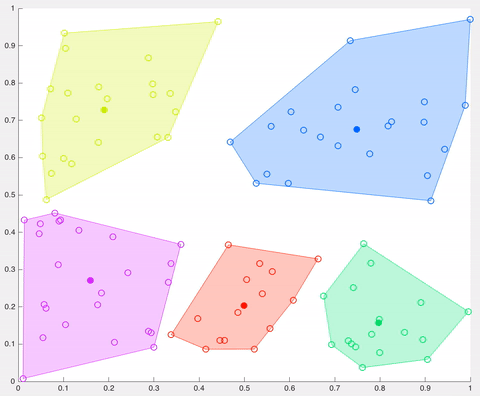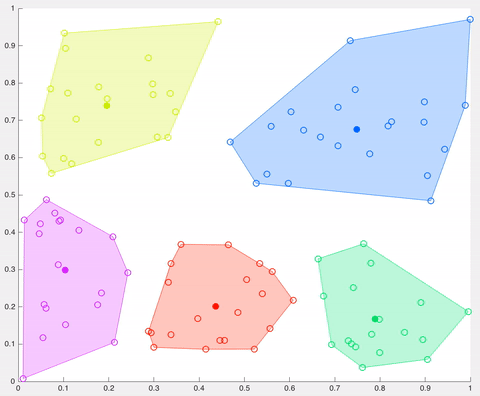
- K centroids are created randomly (based on the predefined value of K)
- K-means allocates every data point in the dataset to the nearest centroid (minimizing Euclidean distances between them), meaning that a data point is considered to be in a particular cluster if it is closer to that cluster’s centroid than any other centroid
- Then K-means recalculates the centroids by taking the mean of all data points assigned to that centroid’s cluster, hence reducing the total intra-cluster variance in relation to the previous step. The “means” in the K-means refers to averaging the data and finding the new centroid
- The algorithm iterates between steps 2 and 3 until some criteria is met (e.g. the sum of distances between the data points and their corresponding centroid is minimized, a maximum number of iterations is reached, no changes in centroids value or no data points change clusters)
Choosing the right amount of K
One commonly used approach is testing different numbers of clusters and measure the resulting sum of squared errors, choosing the K value at which an increase will cause a very small decrease in the error sum, while a decrease will sharply increase the error sum. This point that defines the optimal number of clusters is known as the “elbow point”, and can be used as a visual measure to find the best pick for the value of K.

Leave a comment