K Means
Clustering is a technique widely used to find groups of observations (clusters) that share similar characteristics. This process is not driven by a specific ...

K Means
Clustering is a technique widely used to find groups of observations (clusters) that share similar characteristics. This process is not driven by a specific ...
K-Means Exercise
Exercise from Jose Portilla Python for Data Science Bootcamp.
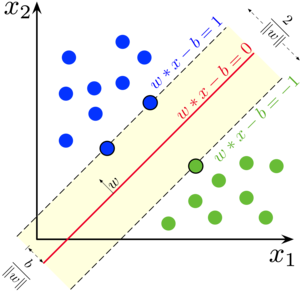
Support Vector Machine
The support vector machine is a generalization of a classifier called maximal margin classifier. The maximal margin classifier is simple, but it cannot be ap...
Support Vector Machine Exercise
Exercise from Jose Portilla Python for Data Science Bootcamp.
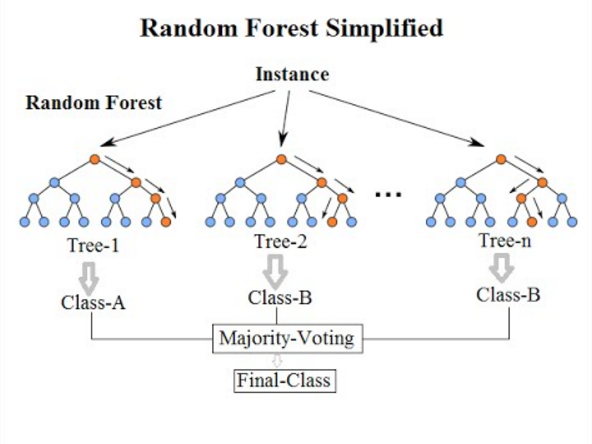
Random Forest
Bagging is an ensemble algorithm that fits multiple models on different subsets of a training dataset, then combines the predictions from all models. Random ...
Decision Tree
Decision trees are very popular machine learning algorithm. They are popular because a variety of reasons, being their interpretability probably their most i...
Decision Tree and Random Forest Exercise
Exercise from Jose Portilla Python for Data Science Bootcamp.
Categorical Encoding 2
Another reference and shared post from https://www.mygreatlearning.com/blog/label-encoding-in-python/
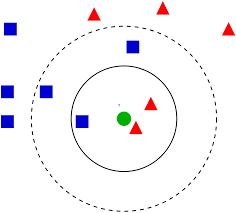
K Nearest Neighbour
K Nearest Neighbour (KNN) works by choosing the best $k$ of neighbour. Neighbour by definition is a person living near or next door to the speaker or person ...
K Nearest Neighbour Exercise
Exercise from Jose Portilla Python for Data Science Bootcamp.